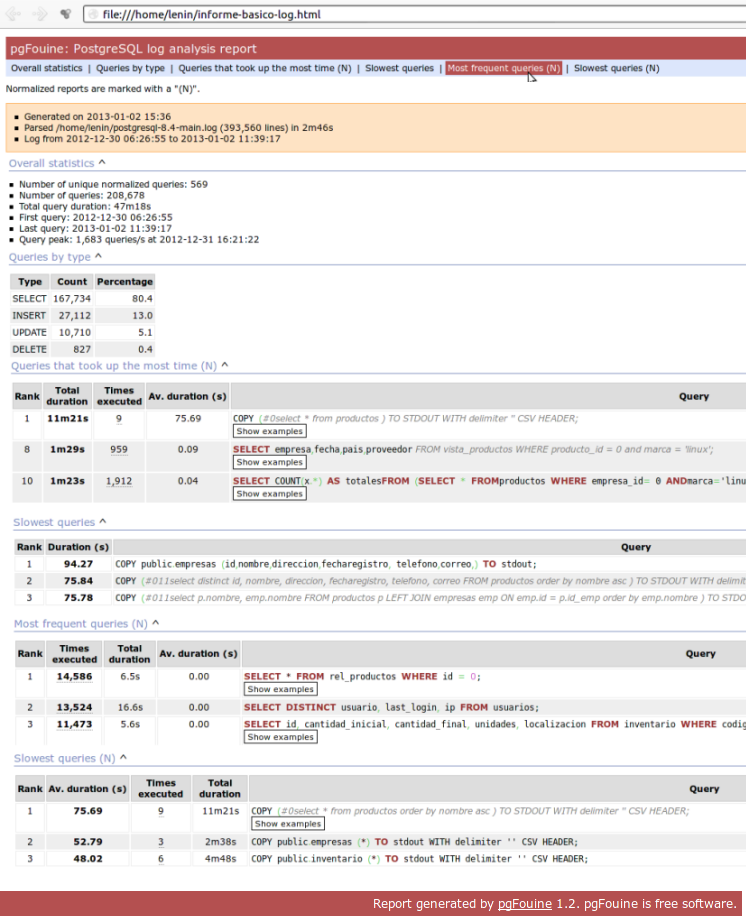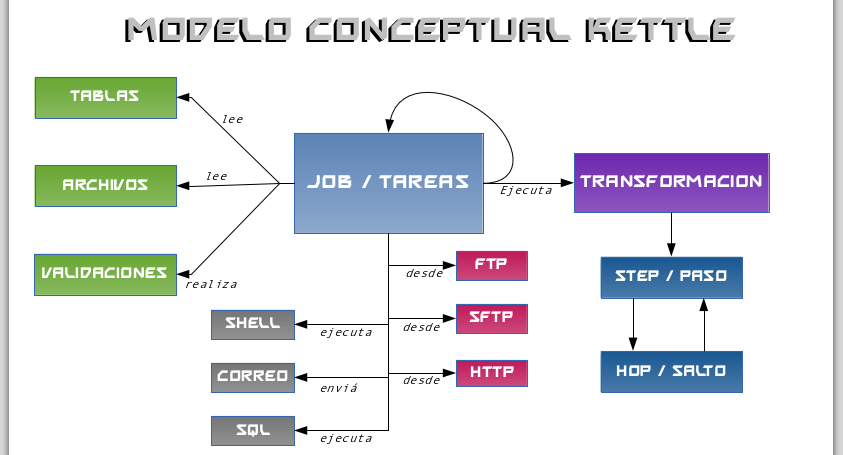
Pentaho Data Integration (Kettle) en Debian Wheezy
La suite de inteligencia de negocios Pentaho, entre las distintas soluciones que ofrece cuenta con la herramienta de Integración de data (Pentaho Data Integration) mejor conocida como Kettle cuyo nombre es un acrónimo recursivo de «Kettle Extraction Transformation Transportation & Loading Environment». Dicha herramienta permite realizar operaciones de ETL (Extraction, Transformation and Load), sobre diversas […]
Pentaho Data Integration (Kettle) en Debian Wheezy Leer más »
Bases de Datos