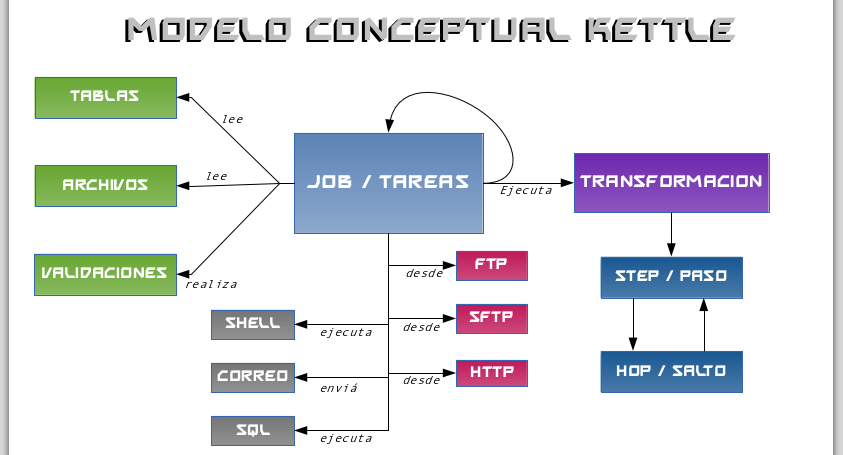
La suite de inteligencia de negocios Pentaho, entre las distintas soluciones que ofrece cuenta con la herramienta de Integración de data (Pentaho Data Integration) mejor conocida como Kettle cuyo nombre es un acrónimo recursivo de «Kettle Extraction Transformation Transportation & Loading Environment». Dicha herramienta permite realizar operaciones de ETL (Extraction, Transformation and Load), sobre diversas fuentes de datos y con múltiples opciones para ello.
Pentaho Kettle Data Integration en Debian
La pagina web oficial de Kettle es http://kettle.pentaho.com/ en la cual se llega al repositorio en SourceForge para descargar la ultima versión estable. A la fecha de esta entrada la ultima versión disponible es la 4.4
El URL directo para descargar es http://sourceforge.net/projects/pentaho/files/latest/download y si tiene alguna confusión haga clic en: pdi-ce-4.4.0-stable.tar.gz
Descomprimir el archivo que descargamos con clic derecho o por terminal así:
tar xvzf pdi-ce-4.4.0-stable.tar.gz
lo cual generara el directorio data-integration/ que a su vez contiene:
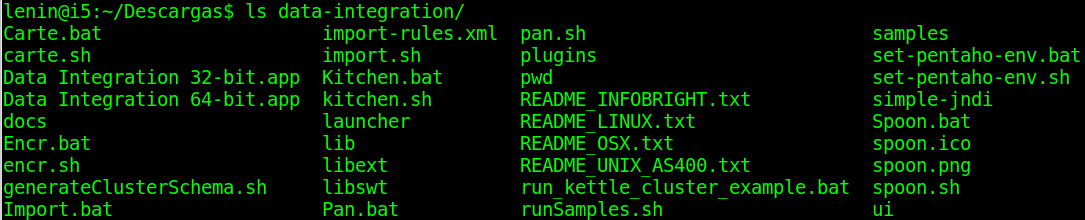
Kettle no requiere un proceso de instalación especifico, en realidad es un ejecutable ya que es una aplicación basada en java usando el motor de aplicaciones de eclipse, por lo cual usted deberá tener en su instalación de Debian, Ubuntu, Canaima o lo que este usando el entorno de ejecución de Java (Java Runtime Environment ) lo cual obtiene mediante:
#aptitude install openjdk-7-jre
Paso siguiente ejecutaremos el archivo spoon.sh
lenin@i5:~/Descargas/data-integration$ cd data-integration/
lenin@i5:~/Descargas/data-integration$ ./spoon.sh

Luego levantara un dialogo que pregunta por repositorios de conexión y posterior le mostrara un dialogo de tips de spoon cancele ambos.
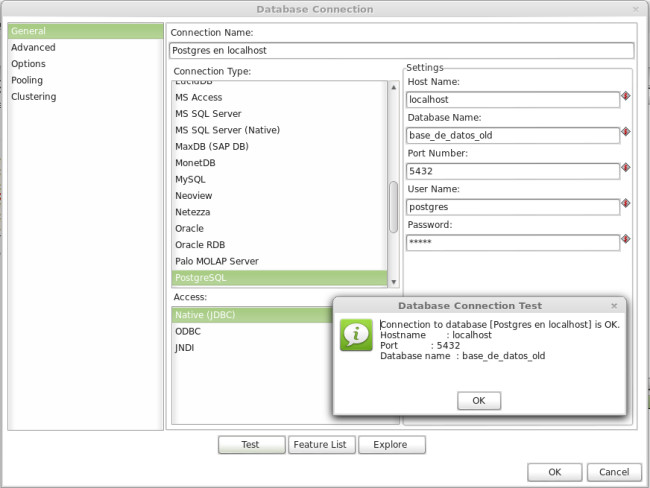
Establecer la conexión de Kettle con nuestras bases de datos libres
Para llegar al área de las conexiones a base de datos recorreremos : Transformations -> Views -> Databases Connections y doble clic
En este dialogo de kettle nos da opción de usar los siguientes motores de bases de datos: AS/400, Apache Derby, Borland Interbase, Calpont InfiniDB, Exasol 4, ExtenDB, Firebird SQL, Generic database, Greenplum, Gupta SQL Base, H2, Hadoop Hive, Hypersonic, IBM DB2, Infobright, Informix, Ingres, Ingres VectorWise, InterSystems Cache, KingbaseES, LucidDB, MS Access, MS SQL Server, MaxDB (SAP DB), MonetDB, MySQL, Neoview, Netezza, Oracle, Oracle RDB, Palo MOLAP Server, PostgreSQL, Remedy Action Request System, SAP ERP System, SQLite, Sybase, SybaseIQ, Teradata, UniVerse database, Vertica, dBase III, IV y 5.

Si se preguntan por que no están las bases de datos libres NoSQL mas usadas en la lista, la respuesta es que las ubica en una sección que llama BigData, donde se encuentra Avro, Cassandra, CouchDB, Hadoop, HBase, MapReduce y MondoDB. Con sus respectivos espacios y documentación:
BigData http://wiki.pentaho.com/display/BAD/Pentaho+Big+Data+Community+Home
Kettle + MongoDB http://kettle.bleuel.com/2012/05/23/kettle-and-nosql-mongodb/ http://wiki.pentaho.com/display/BAD/MongoDB
Kettle + Cassandra http://wiki.pentaho.com/display/BAD/Cassandra
En efecto muchas opciones para manipulación e integración de fuentes de datos, pero nosotros en esta entrada trabajaremos con PostgreSQL el motor de bases de datos en software libre mas completo.
.
Nos conectaremos a PostgreSQL de esta manera:
Ejemplo practico ketle pdi
Realizaremos una transformación sencilla. Leeremos las entradas de este blog mediante el rss ( http://leninmhs.wordpress.com/feed/ ) y enviaremos los datos de las entradas a un archivo plano de nombre salida-rss-leninmhs.txt y a su vez a una tabla en nuestra base de datos PostgreSQL.
Para ello estando en la vista de diseño, seleccionaremos que la entrada (Input) sera un canal RSS, indicaremos el url del mismo, luego limitaremos el texto de las descripciones de las entradas a 50 caracteres y 100 caracteres respectivamente (texto y html) esto lo hacemos en la opción Transform -> String Cut , luego de esta transformación seleccionaremos dos salidas para nuestra tarea, para ello Output -> Text File Output y Output -> Table Output. En cada salto tenemos la opciones con dar doble clic o posicionando el mouse sobre cada cuadro (hop).
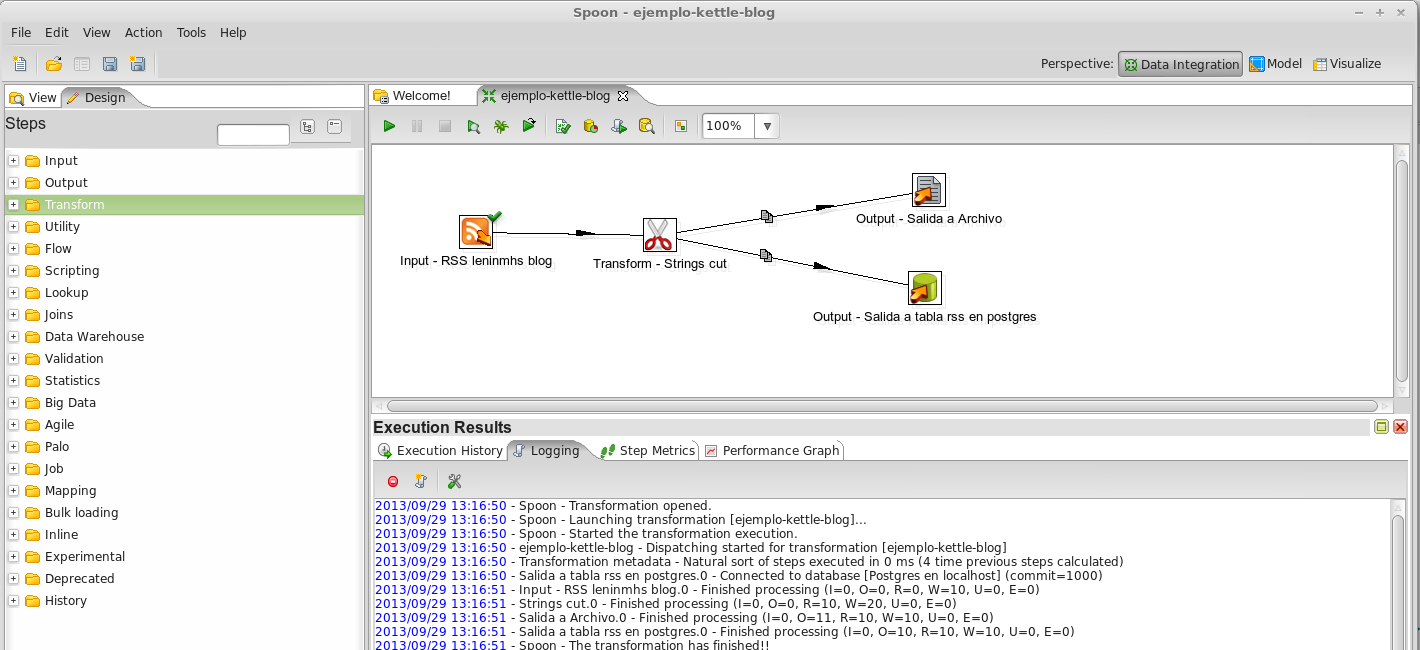
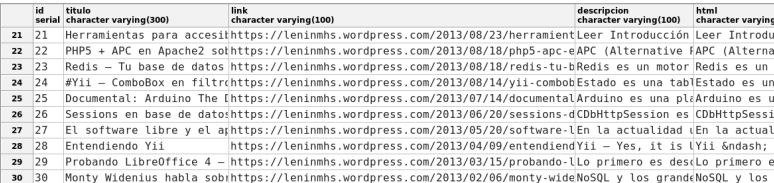
El resultado de ejecutar esta tarea es:

.
La sencilla tarea que acabamos de guiar para su realización, pudiera perfectamente ser resuelta, logrando el mismo objetivo con su lenguaje de programación favorito, pero para ello deberá usar alguna librería que interprete el rss, alguna función o expresión regular que solo permita cierta cantidad de texto a las cadenas, contar con el driver de conexión a la base de datos llamar los métodos que interactúan con ella y claro el trabajo de manipulación de archivos de texto desde el lenguaje de programación elegido para esta tarea.
¿Que solución es mas eficiente herramientas ETL como Kettle ó lenguajes de programación y técnicas relacionadas?
La respuesta esta en la pericia y las habilidades de quien se disponga a asumir la tarea, en relación a las opciones planteadas. Si su organización cotidianamente requiere manipular volúmenes de datos, entonces lo mas idóneo es adoptar herramientas de ETL como la que repasamos en esta entrada.



Se puede instalar kettle en debian sin entorno grafico?
Hola Durkis, no se puede levantar Kettle sin el entorno grafico puesto que es una herramienta grafica, lo que si se puede es correr transformaciones y realizar algunas otras tareas por linea de comando (terminal) y para ello si no necesitarias entorno grafico, para ello podrias usar PAN http://wiki.pentaho.com/display/EAI/Pan+User+Documentation
Se puede instalar kettle en debian sin entorno grafico?