Aunque el común denominador suele referirse a estas soluciones de base de datos como cluster o clusterización por el hecho de que normalmente implica varios servidores, varias instancias o instalaciones de bases de datos distribuidas tal vez hasta geográficamente, lo correcto es referirse a «Alta Disponibilidad» del ingles «High Availability« (en muchos textos se abrevia HA) por que nos indica que la prioridad es «Mantener la Continuidad Operativa» de nuestro servicio, de nuestras operaciones, de la infraestructura tecnológica que soporta un negocio que simplemente no se puede dar el lujo de detenerse, o en caso de falla tiene que recuperarse y restaurarse bajo unas reglas definidas previamente, es por ello que hablamos de Alta Disponibilidad y no de cluster.
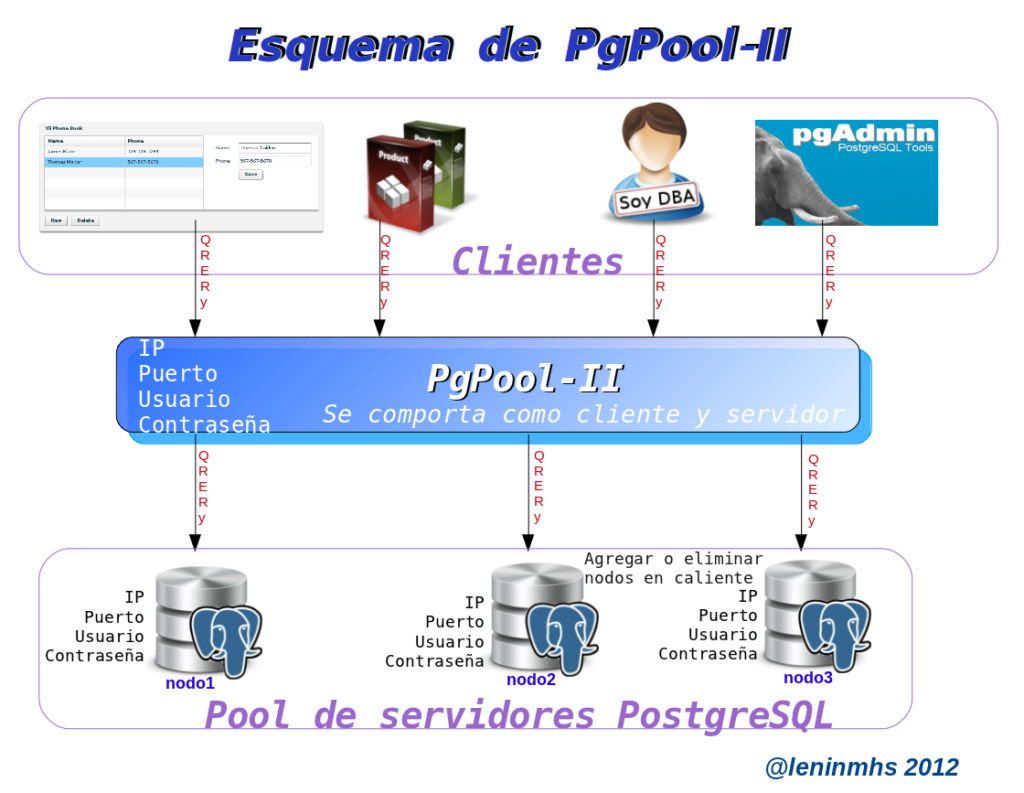
Pgpool-II es una de las mejores y mas completa herramienta para brindar soluciones de alta disponibilidad en el manejador de bases de datos libres PostgreSQL. PgPool-II es software libre que trabaja como intermediario (middleware) entre clientes que se conecten contra postgres (psql, pgadmin, DBA’s, software, aplicativos, etc..) y otras instancias de bases de datos (nodos) para distribuir el trabajo o la carga entre los distintos nodos con los que cuente nuestro diseño o implementación de alta disponibilidad.
Los clientes ven y se conectan a PgPool a través de una cadena de conexión común y silvestre como si fuera una base de datos mas, y a su vez cada uno de los nodos ven a PgPool como si fuera un cliente mas, de ahí que PgPool podría ser considerado desde este punto de vista como cliente y servidor al mismo tiempo.

Alta Disponibilidad PgPool
PgPool sobresale sobre otras herramientas de software libre que brindan o buscan brindar alta disponibilidad para PostgreSQL por tener soporte para las siguientes características:
- Agrupación de Conexiones ( Connection Pooling )
PgPool-II guarda las conexiones establecidas con los servidores PostgreSQL (nodos), y las vuelve a usar cada vez que una nueva conexión con las mismas propiedades (usuario, base de datos, puerto, versión del protocolo) es necesitada. Esto reduce la sobrecarga de la conexión y mejora considerablemente el rendimiento general de los sistemas.
- Replicación ( Replication )
PgPool-II puede gestionar múltiples servidores PostgreSQL. Habilitando la funcionalidad de replicación permite crear una copia de seguridad en tiempo real de dos (2) o mas servidores Postgres, de modo que en caso de fallo de alguno de esos nodos el servicio puede continuar sin interrupción.
- Balanceo de Carga ( Load Balance )
Si una base de datos se replica (porque se ejecuta en modo replicación o bien en modo maestro / esclavo), la ejecución de una consulta tipo SELECT en cualquier de los servidores devolverá siempre el mismo resultado. pgPool-II toma ventaja de la función de replicación con el fin de reducir la carga sobre cada servidor PostgreSQL. Lo hace mediante la distribución de las consultas SELECT entre los servidores disponibles, mejorando el rendimiento global del sistema.
En un escenario ideal, el rendimiento de lectura podría mejorar proporcionalmente a la cantidad de servidores PostgreSQL. El rendimiento mejora en proporción al número de servidores PostgreSQL. El balance de cargas funciona mejor en escenarios donde hay una gran cantidad de usuarios que ejecutan múltiples consultas de sólo lectura (read-only), al mismo tiempo.
- Limite de Conexiones excedidas ( Limiting Exceeding Connections )
Existe un limite del máximo numero de conexiones simultaneas o concurrentes que PostgreSQL permite, y nuevas conexiones son rechazadas cuando este limite es alcanzado. Aumentar este numero máximo de conexiones causa un impacto negativo penalizando el rendimiento general del sistema. PgPool-II también tiene un numero máximo de conexiones, pero las conexiones adicionales se pondrán en cola de espera en vez de retornar error inmediatamente.
- Consultas en Paralelo ( Parallel Query )
Utilizando la funciónalidad de consulta en paralelo, los datos se pueden dividir entre los múltiples servidores, de modo que una consulta se puede ejecutar en todos los servidores al mismo tiempo para reducir el tiempo de ejecución global. Las Consultas en paralelo funcionan mejor cuando se buscan datos de gran escala. Este breve articulo se escribe en el marco del 3er Encuentro de Bases de Datos Libres que se realizo el 04/05/2012 realizada por el CNTI en CANTV, las laminas que use son las siguientes:
[slideshare id=12858275&doc=pgpool-lenin-hernandez-120508235241-phpapp01]


Pingback: Explicación somera de Tweets de Tecnología « Leninmhs
Hola, espero me puedas ayudar!!
He configurado pgpool2 en 2 nodos para replicación y me ha funcionado, lo probé creando bases de datos, tablas y registros y todo perfecto, al otro día que fui a realizar pruebas nuevamente, ya no me funcionaba.. Lo instale y configuré en 2 pcs con S.O debian wheezy con postgresql 9.1.. Me podrías decir que puedo probar para que de nuevo funcione o si sabes si ha sucedido en otras oportunidades y como lo han resuelto? Ya he verificado y todo esta como lo configure, Gracias