Aprende Pentaho Data Integration (PDI) con la guía definitiva, donde con ejemplo practico aprenderás desde la instalación hasta realizar transformaciones
HERRAMIENTA (PDI – KETTLE)
¿Que es Kettle?
Es un ambiente de Extracción, Transformación, Transporte y Carga Kettle del tipo Open Source. Básicamente la herramienta Pentaho Data Integration (PDI) debe de seguir estas cuatros etapas en todas sus Transformaciones con Kettle (KTR).
¿Que es Spoon?
Spoon es el entorno gráfico estándar de PDI, mediante esta Interfase Gráfica (UI) podemos diseñar todas los KTR basados en una tecnología Rapid application development (RAD). Las tareas son modeladas tipo Workflow ó flujo de trabajo para coordinar recursos, ejecución y dependencias de actividades Extract, transform and load (extracción, transformación y carga) ETL.
Existen otras herramientas para migración de data que se puede abstraer para ser utilizada con PDI pero para efectos de este manual, utilizaremos el Spoon en su forma estándar.
PDI SPOON KETTLE de Pentaho Data Integration
Características Generales de PDI.
– Fácil de Usar.
100% basado en meta-data.
Menos complejidad al no tener que generar códigos Extras.
Instalación Fácil, Interfase Gráfica sencilla y fácil de mantener.
– Flexibilidad
Nunca obliga a tomar un camino único.
Arquitectura adaptable para extender funcionalidad.
– Arquitectura basadas en estándares modernos.
100% Java con amplio soporte de plataforma.
Mas de 70 objetos de mapeo pre-definidos (pasos y tareas).
Desempeño y escalabilidad empresarial.
– Menores costos de propiedad (TCO)
No hay costos de Licencias.
Ciclos de implantación cortos.
Costos de mantenimiento Reducidos.
LOS PRIMEROS PASOS CON PENTAHO DATA INTEGRATION PDI.
Instalación de PDI.
Lo primero que se debe hacer es descargar la ultima versión disponible en la siguiente url: http://www.pentaho.com/download ó http://sourceforge.net/projects/pentaho/files/latest/download
Teniendo finalmente descargado el archivo pdi-ce-4.4.0-stable.tar.gz se debe descomprimir mediante consola bajo root para que herede los permisos necesarios, lo primero se debe comprobar que se tiene instalado la herramienta “tar”
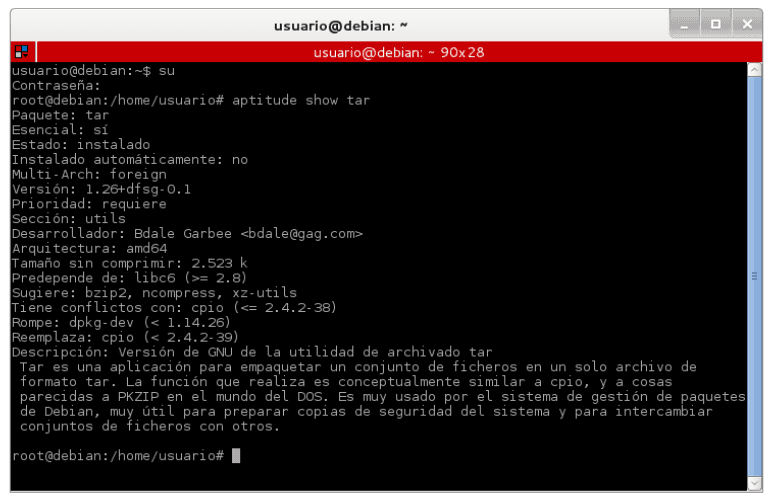
luego ubicamos la ruta de la carpeta mediante un cd + ruta


para descomprimir se coloca el siguiente comando
de tener problemas con algún permiso para la ejecución se debe entregar privilegios root de forma recursiva a todo el proyecto, se puede utilizar la instrucción: #chmod -R 777 + la ruta de la carpeta donde se descomprimió el archivo.

Teniendo ya debidamente descomprimido y con sus respectivos permisos para su ejecución se recomienda ejecutar el archivo spoon.sh atraves de la consola root por sh spoon.sh, ya que de esta forma se puede visualizar las etapas que esta sufriendo la creación y ejecución de los procesos mediante el spoon; debe tenerse en cuenta que se debe instalar previamente openjdk-7-jre ya que el mismo requiere estas dependencias.
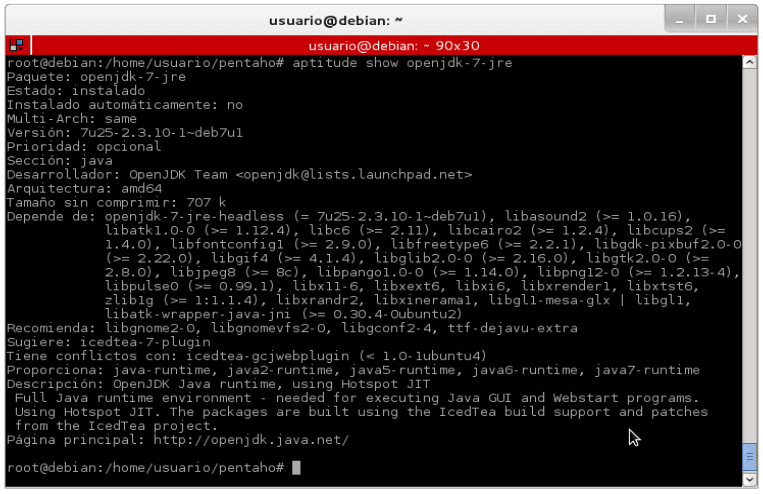


INTRODUCCION A SPOON
Creación de entorno de trabajo basado en un repertorio dispuesto en una base de datos.
Al iniciar por ves primera la aplicación se tendrá la siguiente UI(Fig.1):
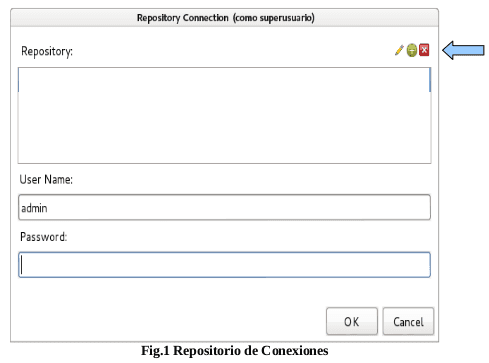
Hacer clip en add button resaltado con la flecha en la (Fig.1), y emergerá la siguiente
pantalla(Fig.2):
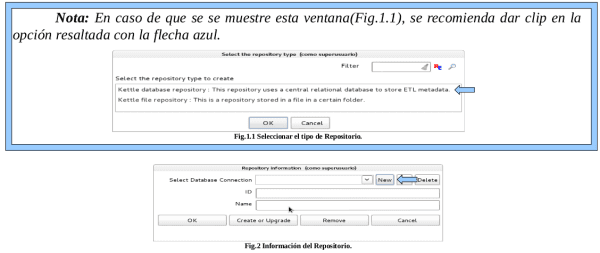
Luego dar clip en new, resaltado con la flecha en (Fig.2), pasar a la siguiente
pantalla(Fig.3) :
Pestaña General:
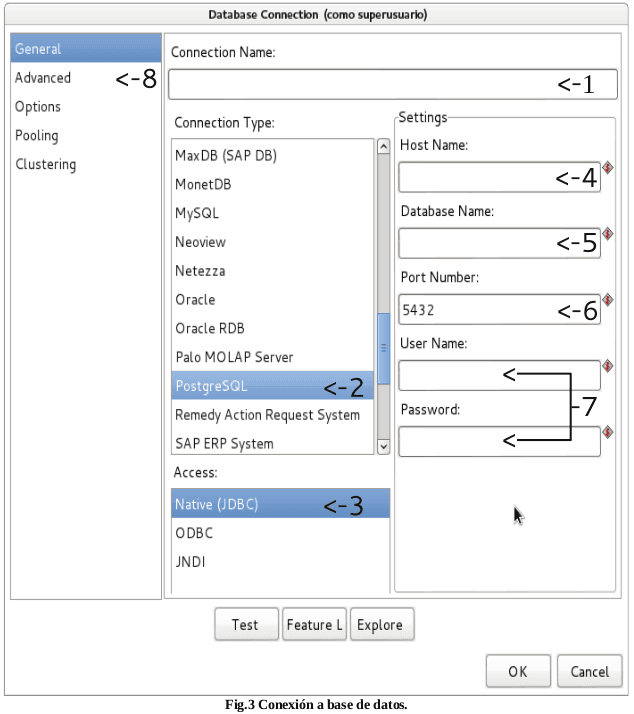
En esta pantalla (Fig.3) es donde se configura las informaciones básicas sobre la conexión
en cuestión, tales como:
1. Nombre de la Conexión.
2. Tipo de Conexión.
3. Método de Acceso
4. Nombre del host ó Ip.
5. Nombre de la base de datos.
6. Puerto de conexión.
7. Usuario y contraseña.
8. Pestaña Advanced
Lo primero a realizar, es darle un nombre a la conexión («Connection Name»). Luego debe seleccionarse en el listado «Connection Type» el tipo de base de datos que utilizaremos. De acuerdo a lo que se elija, las opciones disponibles en «Setting» y «Access» variaran.
Una vez que se han completado los datos de «Connection Name» , «Connection Type», «Connection Access» y «Connection Setting» es recomendable presionar el botón «Test» para verificar la correcta configuración de la conexión.

El botón «Lista de» (Lista de funciones) muestra una tabla con variables y valores relacionados a la conexión actual.

El botón «Explorar» permite navegar interactivamente en la base de datos en cuestión, visualizar tablas, vistas y datos, generar DDL, etc.

Nota: Si al realizar el «Test» se obtiene el siguiente mensaje:
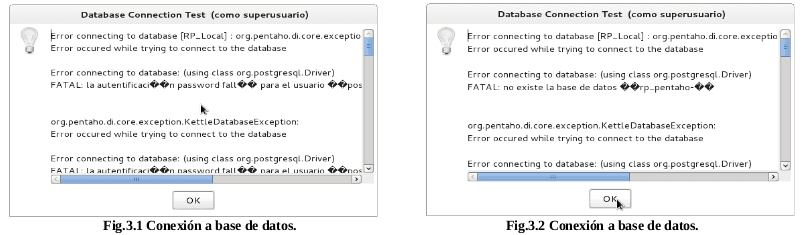
Lo ocurrido en la (Fig.3.1) es que el usuario o la contraseña utilizada para la conexión es incorrecto, en cambio lo señalado en la (Fig.3.2) refiere a que la base de datos, no existe en la conexión.
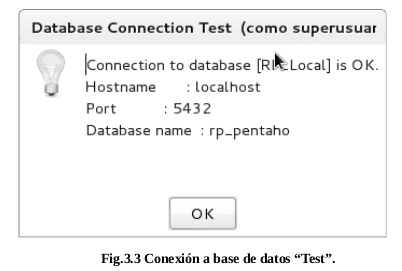
De ser exitosa la conexión se mostrara el siguiente mensaje (Fig 3.3):
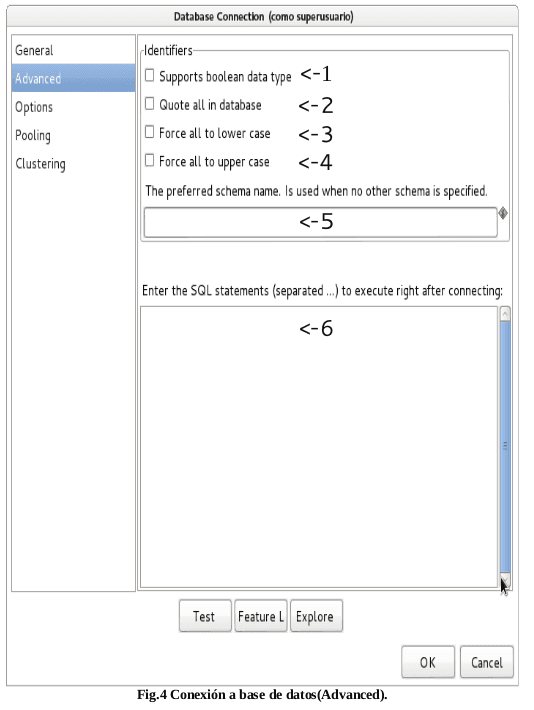
Pestaña Advanced
En esta pestaña (Fig.4) es donde se configura la información avanzada sobre la conexión.
Las opciones disponibles son las siguientes:
1. Soporte de tipo de datos booleanos.
2. Encomillado.
3. Forzar a mayúscula.
4. Forzar a minúscula.
5. Esquema por defecto.
6. Sentencias SQL a ejecutarse luego de realizada la conexión
Nota: Se recomienda habilitar “Soporte de tipo de datos booleanos” ya que extiende la operatividad de la herramienta.
Ya teniendo la conexión exitosa con la base de datos se procede a dar clip en ok luego se coloca el Id y el name del repositorio tal como se muestra en (Fig.5).
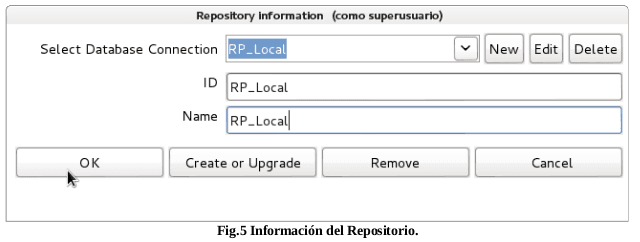
Nota: Previo a la nueva conexión debe tenerse presente que se debe crear la bese de dato para que luego la herramienta para la migración cree las tablas necesarias siguiendo los pasos descrito a continuación.
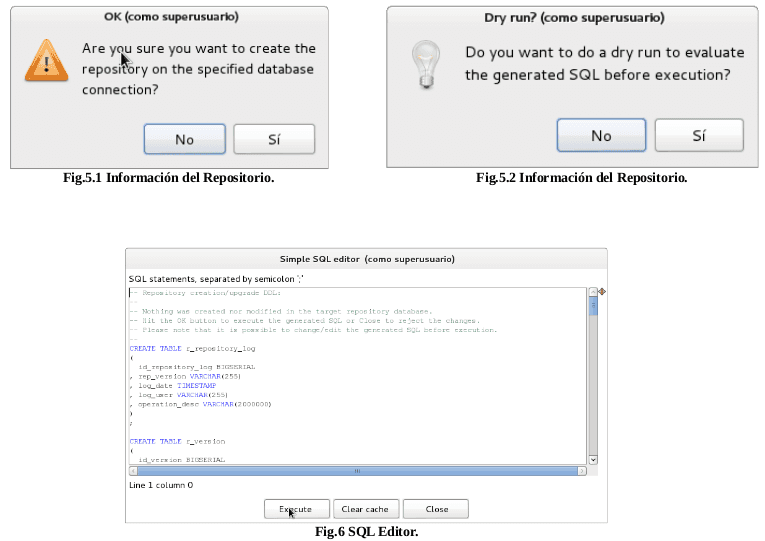
Por ser la primera ves que se crea el repositorio, es necesario establecer la estructura e insertar los datos de inicialización del mismo, esto se logra con el botón de “Create or Upgrade” que se muestra en la (Fig.5 ), seguido a esto se mostrará el mensaje siguiente (Fig 5.1), Cliquear “Sí”, luego en el mensaje (Fig 5.2) Cliquear “Sí”, de tal forma que en la ventana (Fig 6), se de un clip en Execute, ejecutando de esta manera el scrip, generando así una clave por defecto de username: admin y password: admin, para poder ingresar al repositorio.
Culminado el proceso antes descrito cerramos la ventana en el botón “Ok” entrando así satisfactoriamente al repositorio en la base de dato, ver (Fig 7).
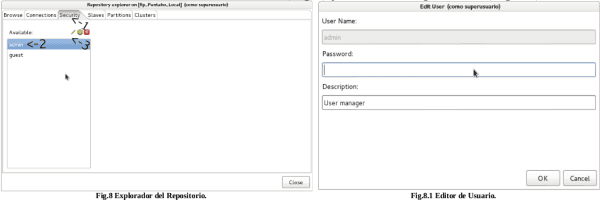
Nota: Es recomendable cambiar de forma inmediata la contraseña admin. A continuación se indican la ruta para el cambio de la misma.
Se ubican en la barra de menú y seleccionan la herramienta “Tools”. Ingresan al sub-menú repositorio “Repository” y ubica la opción “Explore”. Seguidamente aparece un cuadro de dialogo donde, se escoge la pestaña de seguridad “[1].Security” y selecciona el User “[2].admin” y el botón “[3].editar” como se observa en las (Fig.8) y se cambia el password (Fig.8.1).
Teniendo ya la contraseña ya se está preparado par realizar las primeras transformaciones.
Mi primer KTR.
Antes de comenzar con la explicación de algunos objetos de la herramienta, se hace necesario conocer definiciones muy utilizadas en lo referente a PDI.
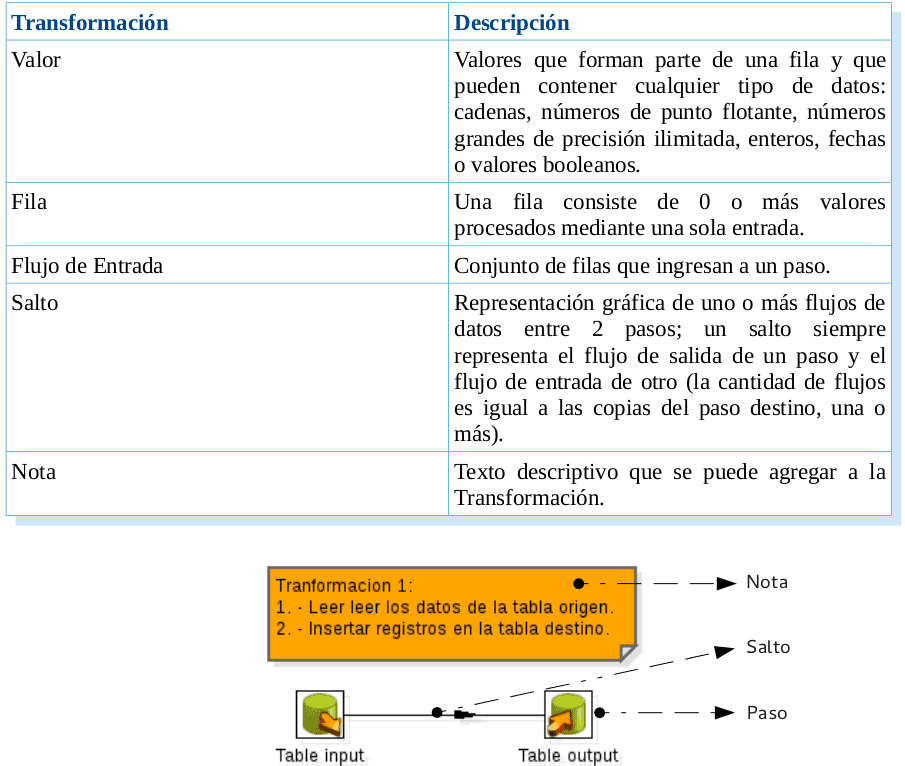
Transformación ó Transformation
La siguiente tabla contiene una lista de definiciones de Transformación, se sugiere ver la (Fig 9):
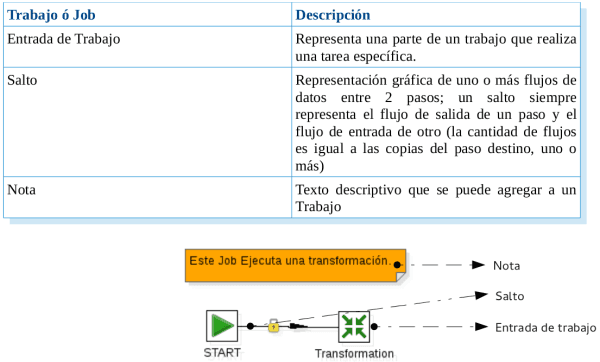
Trabajo ó Job
La siguiente tabla contiene una lista de definiciones de Trabajo:
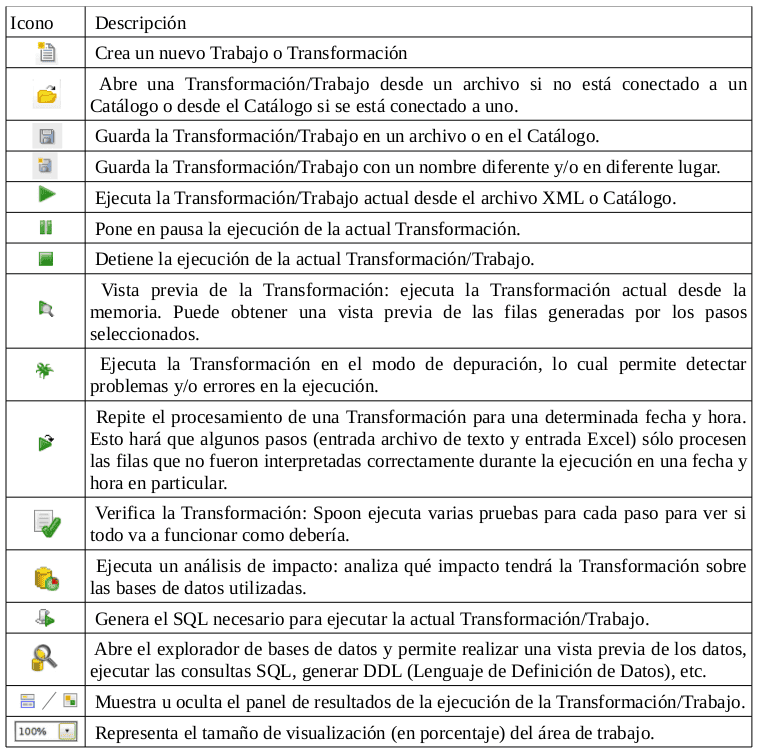
Barra de Herramienta.
La barra de tarea de PDI consta de una serie de iconos que pueden variar según lo que se este realizando, a continuación se detallan cada uno de estos iconos.

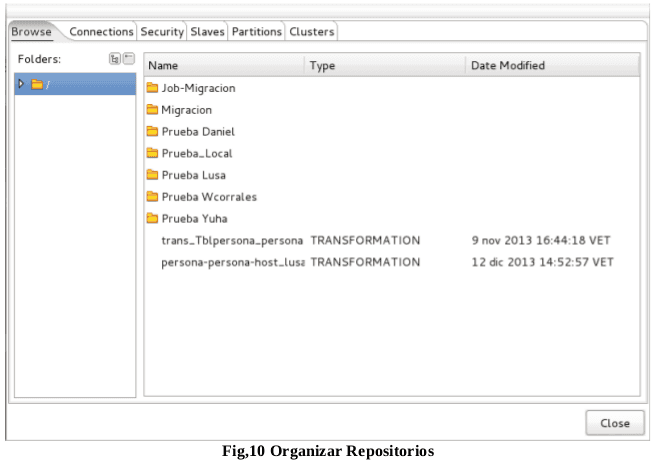
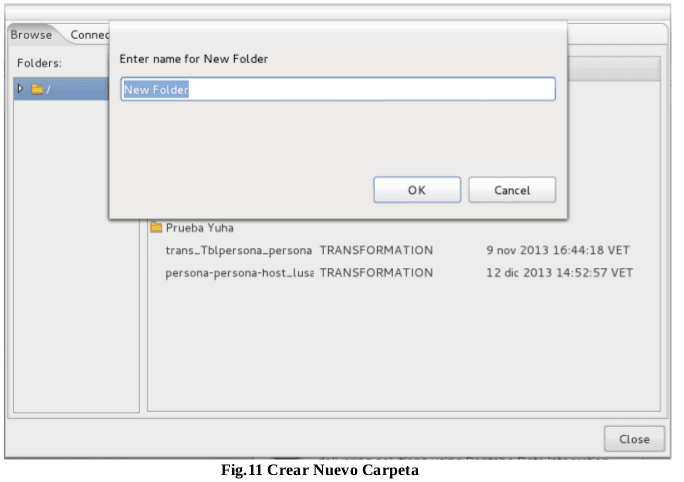
Para comenzar a trabajar se recomienda organizar los repositorios mediante directorios creando para ello carpetas en el “Explore”. La ruta de acceso es barra de menú botón herramientas “Tools”, Ingresa al sub-menú repositorio “Repository” y ubica la opción “Explore”, ó CTRL+E. Ver Fig.10 y Fig.11.
Para crear un KTR se debe ingresar la siguiente ruta File/New/transformation ó CTRL+N; Seguidamente dar cumplimiento al principio de leer, transformar y cargar los datos en el data-receptor.
Se recomienda darle un preview (4) a la data para visualizar si los datos consultados son los correctos, luego se le debe dar ok.
Generalmente luego de esto se incluye una transformación según se requiera, y esta se encuentra en el tree “Trasform”
Para conectar un objeto con el otro se hace mediante un flujo de dirección y este se controla mediante la pulsación de la tecla shift seguida de un clip con el mouse y desplazarlo hasta el objeto que se desea conectar.
Para terminar se necesita cargar la transformación en el receptor, para ello se utiliza los objetos dispuestos en el tree “Output”, generalmente se utiliza el Table output para migrar finalmente la data al receptor. En este objeto se debe conectar la base de datos receptora mediante la interfase de conexión general que fue descrita al principio de este manual. Luego de tener conectada la base de dato, se debe apuntar al schema y la tabla que se quiere cargar.
PRINCIPALES HERRAMIENTAS EN PENTAHO DATA INTEGRATION

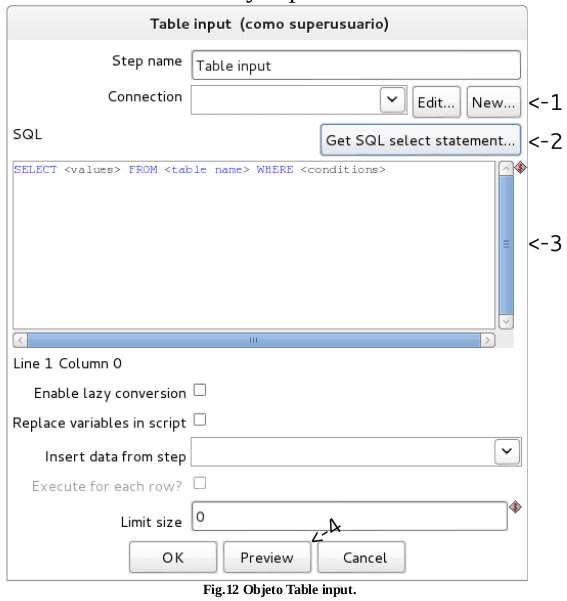
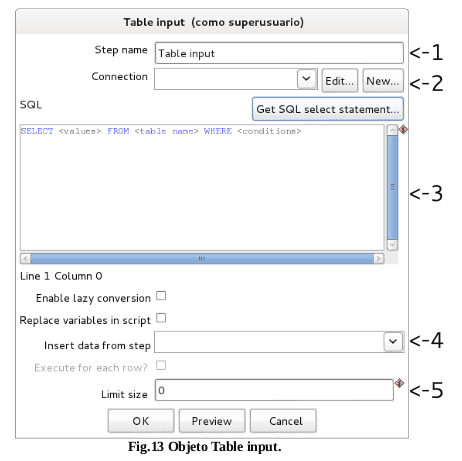
Lee información de una base de datos, utilizando una conexión y SQL, Ver Fig. 13.
Opciones de Entrada de Tablas
1. Step Name: el nombre debe ser único en una misma transformación.
2. Connection: es la conexión de la base de datos de la cual se lee la data.
3. SQL: La sentencia usada para leer la información de la base de datos.
4. Insert data from step:El paso de donde vienen los parámetros para la sentencia SQL.
5. Limit: El número de líneas a leer de la base de datos.
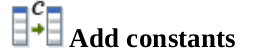
Añade constantes a un flujo.
Elementos más relevantes:
1. Especifica un nombre
2. El tipo de dato.
3. Especificar el formato para convertir el valor.
4. Especifica la Longitud.
5. Introducir el valor como una cadena de caracteres
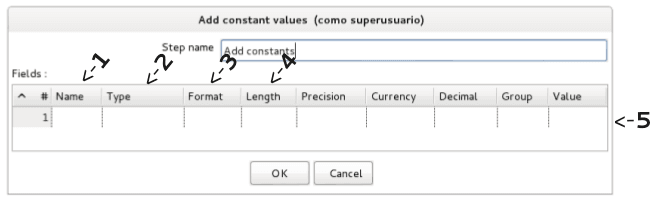
.
Nota: Si la representación en cadena de caracteres de un campo es igual al valor especificado, entonces el valor de salida es cambiado a nulo (vacío).

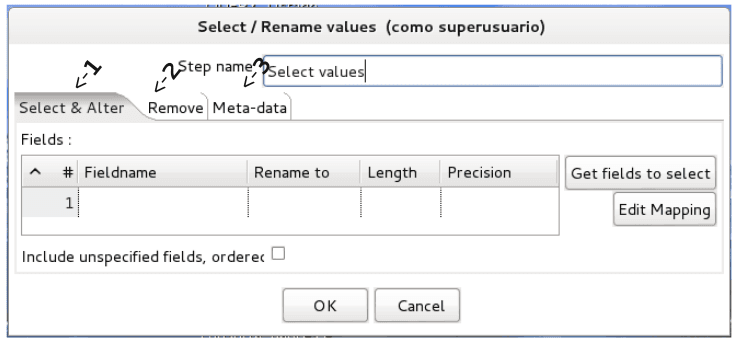
.Este paso es usado para
• Seleccionar/Remover campos del flujo del proceso
• Renombrar campos
• Cambiar la longitud y o precisión de los campos
Se proveen 3 Pestañas:
1. Select & Alter (Seleccionar y Alterar): Especifica el nombre y el orden exacto
en que los campos deben ser colocados en la fila de salida.
2. Remove (Remover): Especifica los campos que deben ser removidos de la fila
de salida.
3. Meta-data: Cambia el nombre, tipo, longitud y precisión (la meta-data) de uno o mas campos.
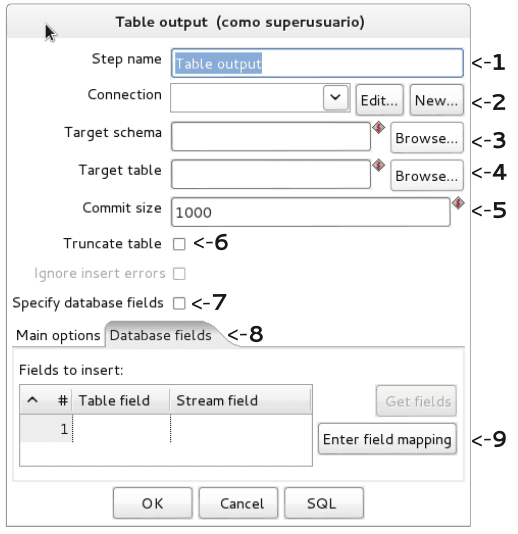
Insertar (únicamente) información en una tabla de base de datos.
Opciones
1. Step name: Esta casilla se coloca el nombre referencial de la inserción.
2. Conection: Se elige la conexión para la inserción de la data.
3. Target schema: Muestra o elige el esquema donde se insertara los datos.
4. Target table : Esta opción es para ubicar la tabla dentro de un schema conectado previamente.
5. Commit size : Bucle de registros pre-procesados para su inserción.
6. Truncate table : Opcional para truncar la tabla antes de su la inserción.
7. Ignore insert errors : Evita una interrupción si ocurre un error al insertar.
8. Specify database fields : Esta se debe tildar para realizar el mapeo de los datos en la pestaña Database fields.
9. Enter field mapping: Se debe tildar la opción: Specify database fields, para realizar el mapeo de la data.
Reemplaza cadenas de caracteres (“string”) por otro valor de tipo string.
Opciones Disponibles:
1. In stream field: En esta casilla se indica cual es el campo, en donde se reemplazara el valor afín.
2. Out stream field: Esta casilla permite cambiar el nombre del campo resultante.
3. Search: Es en esta casilla donde se coloca cual es el carácter que se va ha buscar para que posteriormente sea re-emplazado.
4. Replace with: Aquí se coloca el carácter que reemplazara el carácter buscado.
5. Replace with field: En esta casilla se configura si se necesita reemplazar el contenido con los registros de otro campo.
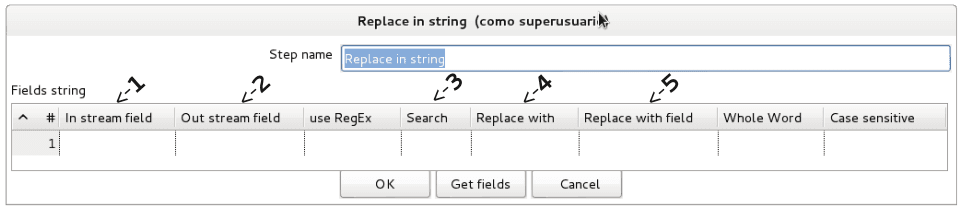
Nota: se debe combinar esta herramienta con “Select values” en los casos donde se valla a reemplazar tipos de datos diferentes a String, haciendo entonces un cambio a tipo de datos String.
..:: Descargar Manual de Pentaho Data Integration PDI – KETTLE en PDF ::..
Autor: Winter Xavier Corrales Piñero
Profesión: Ingeniero de Sistema