Bucardo es una herramienta de replicación de datos para el SGBD PostgreSQL. Este sistema es asíncrono, se puede realizar sincronización de tipo maestro-esclavo y maestro-maestro. Esta desarrollado con el lenguaje de programación Perl y su secreto para ser asíncrono es PL/Perl, creando en la base de datos unos script fabulosos. Es Software Libre y esta liberado con la licencia BSD.
¿Por qué Bucardo?
1.- Para PostgreSQL.
2.- Facilidad de usar.
3.- Estabilidad.
4.- Mantenimiento activo por su comunidad.
5.- Software Libre.
6.- Permite sincronización de maestro-maesto.
7.- No es necesario la replicación de toda la base de dato (se puede especificar los esquemas y las tablas.).
8.- Sincronización de tipo asíncrona.
Problema solucionado con Bucardo.
En la organización se necesitaba realizar una aplicación de tipo distribuida donde si no existía conexión a internet continuara la operación, pero cuando existiera conexión, se sincronizaran las bases de datos (esquema o tabla) de todos los nodos involucrados (se necesitaba que todos los nodos conservaran la misma información).
Leyendo en la web nos conseguimos las siguientes definiciones importantes para entender en el proceso:
Replicación: Es el proceso de intercambiar datos de transacciones para asegurar la consistencia entre nodos de bases de datos redundantes. Es el proceso de copiar y mantener los elementos de una base de datos en múltiples bases de datos que forman un sistema de bases de datos distribuido.
Alta disponibilidad (high availability): Se puede incrementar la disponibilidad de una base de datos mediante la replicación en un sistema distribuido. Si una de las máquinas del sistema falla, las otras podrán satisfacer las necesidades del cliente.
Balance de carga (load balancing): La replicación se puede utilizar para hacer un balance de carga. Ésta es una técnica usada para compartir el trabajo a realizar entre varias computadoras.
Soporte para aplicaciones de alto consumo: Se puede satisfacer las necesidades de ciertos clientes que requieren un alto consumo en consultas, que sería muy costo en rendimiento, o hasta imposible, en una base de datos sin replicación.
Confiabilidad: Debido a que existen varias copias de los datos disponibles en el sistema, se cuenta con un mecanismo confiable de recuperación de datos ante fallos en algún nodo.
Replicación síncrona: Una transacción de modificación de datos no es considerara hasta que todos los servidores confirmaron la transacción. Esto garantiza que ante un eventual error en la transacción no se perderán datos y que todos los servidores de carga balanceada devolverán resultados consistentes sin importar cual de los servidores haya sido consultado.
Replicación asíncrona: Permiten un retraso entre el momento en que se realiza una consulta y el tiempo de propagación a los otros servidores. Aquí existe la posibilidad de que algunas transacciones se pierdan cuando se cambia a un servidor de respaldo y que los servidores de carga balanceada devuelvan resultados ligeramente antiguos. La comunicación asíncrona es utilizada cuando la comunicación sincrónica sería muy lenta.
Asynchronous Multimaster Replication: Para los servidores que no están conectados regularmente, mantener los datos consistentes a través de estos es un gran desafío. Usando este tipo de replicación, cada servidor trabaja de manera independiente y periódicamente se comunica con los otros servidores para identificar las transacciones conflictivas. Estos conflictos pueden ser resueltos por el usuario o por reglas de resolución de conflictos.
Synchronous Multimaster Replication: En este tipo de replicación, cada servidor puede aceptar solicitudes de escritura y los datos modificados son transmitidos desde el servidor original al resto de los servidores antes de que cada transacción sea confirmada. Una fuerte actividad de escritura puede causar un bloqueo excesivo, causando un bajo rendimiento. Las solicitudes de lectura pueden ser enviadas a cualquier servidor.
Transaction Log Shipping: Los servidores warm standby y hot standby pueden mantenerse actualizados leyendo un flujo de registros de WAL (write-ahead log). Si el servidor principal falla, el servidor standby contiene casi todos los datos del servidor pincipal, y puede ser rápidamente convertido en el nuevo servidor master. Este modelo puede ser sincrónico o asincrónico, y sólo puede ser implementado para el servidor de base de datos completo.
Trigger-Based Master-Standby Replication: Este tipo de replicación envía todas las consultas de modificación de datos al servidor master. El servidor master envía asincrónicamente las modificaciones de los datos al servidor standby. Éste último puede responder consultas de sólo lectura mientras el servidor master esta corriendo.
Instalación de Bucardo en ambiente Debian GNU/Linux Squeeze con PostgreSQL 8.4.
Se supone que tenemos PostgreSQL 8.4 instalado y corriendo, bajo Debian GNU/Linux Squeeze u otras maquinas que se tenga acceso a la base de datos. Bucardo no corre bajo ambiente de sistema operativo Windows por ahora según su sitio oficial, pero eso no quiere decir, que no se pueda sincronizar bases de datos PostgreSQL bajo ambiente Windows. En realidad en la practica la institución no tiene sus máquinas bajo GNU/Linux, solo unos cuantos servidores.
Se requiere ejecutar el comando como root: «aptitude install bucardo libdbix-safe-perl libdbd-pg-perl postgresql-plperl-8.4«
Luego se edita el archivo instalado en /usr/bin/bucardo_ctl en la linea donde se ubica «my $default_bucardo_password» cambiando el valor asignada a la variable por una clave que luego se va a colocar en el usuario Bucardo en base de dato.
Procedemos a instalar los lenguaje plpgsql y plperlu por medio del Shell de PostgreSQL, por Pgadmin3 o phppgadmin (el que maneje mejor o mas cómodo te parezca), en las bases de datos, con las siguientes lineas:
«CREATE LANGUAGE plpgsql;
CREATE LANGUAGE plperlu;»
Se crea el usuario «bucardo» con todas la permisologias en las bases de datos donde se vallan a realizar la sincronización, con la misma clave colocada en el script de bucardo en el segundo paso de la instalación.
Para realizar la sincronización Bucardo necesita su propia base de datos con todas las configuraciones necesarias. Esta base de datos se creara en el nodo donde se realizaran las consultas y sincronización principal con el siguiente comando en shell: «psql -h localhost -U postgres < /usr/share/bucardo/bucardo.schema«
Configurando las sincronizaciones en Bucardo.
Lo primero es saber que no se va a realizar balanceo de carga ni alta disponibilidad (para eso se necesita otras herramientas, como por ejemplo, Pgpool-II y Heartbeat). En este caso se necesita 4 base de datos que se encuentren en linea, distribuida y con los datos actualizados en todas, todas tienen que ser de tipo master ya que en cada una se van a realizar operaciones CRUD (Create, Read, Update, Delete).
Buscamos (por medio de shell, Pgadmin3 o phppgadmin) la base de datos “bucardo” en el servidor principal, en el esquema “bucardo” se encuentran varias tablas que vamos a manipular. La primera tabla es “db”, esta tabla contiene la información de los host y base de datos a sincronizar, realizamos unos INSERT en la tabla para darle la información de los nombres, nombre de la base de datos (no necesariamente tiene que ser el mismo nombre en todos los host), dirección IP, usuario para realizar la verificación y las operaciones CRUD (en este caso seria “bucardo” previamente creado) y contraseña de este usuario.
INSERT INTO bucardo.db (name, dbname, dbhost, dbuser, dbpass) VALUES (‘localhost’, ‘repli’, ‘127.0.0.1’, ‘bucardo’, ‘bucardo’);
INSERT INTO bucardo.db (name, dbname, dbhost, dbuser, dbpass) VALUES (‘remoto001’, ‘repli’, ‘192.168.1.3’, ‘bucardo’, ‘bucardo’);
INSERT INTO bucardo.db (name, dbname, dbhost, dbuser, dbpass) VALUES (‘remoto002’, ‘repli’, ‘192.168.1.4’, ‘bucardo’, ‘bucardo’);
INSERT INTO bucardo.db (name, dbname, dbhost, dbuser, dbpass) VALUES (‘remoto003’, ‘repli’, ‘192.168.1.5’, ‘bucardo’, ‘bucardo’);
Realizamos INSERT en la tabla “goat” para indicarle a Bucardo que esquema, cual tabla se va a sincronizar y que tipo de resolución de conflicto se va a realizar (existen diferentes tipos, el ejemplo se va a realizar con el tipo “latest” que es aplica la lógica en cual información esta reciente cambiada. También se puede realizar y personalizar esta opción según la página oficial de Bucardo para mejorar y personalizar la lógica del negocio).
INSERT INTO bucardo.goat (db, schemaname, tablename, standard_conflict) VALUES (‘localhost’, ‘public’, ‘tabla’, ‘latest’);
INSERT INTO bucardo.goat (db, schemaname, tablename, standard_conflict) VALUES (‘remoto001’, ‘public’, ‘tabla’, ‘latest’);
INSERT INTO bucardo.goat (db, schemaname, tablename, standard_conflict) VALUES (‘remoto002’, ‘public’, ‘tabla’, ‘latest’);
Se inserta en la tabla “herd” la siguiente información:
INSERT INTO bucardo.herd(name) VALUES (‘HERD_LOCALHOST’);
INSERT INTO bucardo.herd(name) VALUES (‘HERD_REMOTO001’);
INSERT INTO bucardo.herd(name) VALUES (‘HERD_REMOTO002’);
Necesitamos asociar la tabla «herd» con la «goat», esto es necesario ya que podemos tener multiples tablas para las sincronizaciones (en este ejemplo solo tenemos una pero se puede dar el caso donde se necesite sincronizar diferentes tablas y diferentes esquemas). Esta asociación se realiza en la tabla «herdmap» con el siguiente comando SQL:
INSERT INTO bucardo.herdmap(herd,goat) SELECT ‘HERD_LOCALHOST’, id FROM bucardo.goat WHERE db = ‘localhost’;
INSERT INTO bucardo.herdmap(herd,goat) SELECT ‘HERD_REMOTO001’, id FROM bucardo.goat WHERE db = ‘remoto001’;
INSERT INTO bucardo.herdmap(herd,goat) SELECT ‘HERD_REMOTO002’, id FROM bucardo.goat WHERE db = ‘remoto002’;
Vamos a realizar las sincronizaciones propiamente dichas en la tabla «sync», colocando el nombre de la sincronización, el herd que vamos a colocar como información para las tablas, el nombre del host que va a recibir o enviar la información y el tipo de sincronización (en este caso vamos a realizar con el tipo «swap», ya que este tipo nos permite sincronizar dos maestros, haciendo que sea bidireccional los datos. Existen otros 2 tipos de sincronización pero es para ser tipo maestro-esclavo y para ser ese tipo de sincronización yo utilizaria Pgpool2 ya que se puede balancear las cargas y otros servicios que no nos proporciona bucardo.)
INSERT INTO bucardo.sync(name, source, targetdb, synctype) VALUES (‘localhostremoto001’, ‘HERD_LOCALHOST’, ‘remoto001’, ‘swap’);
INSERT INTO bucardo.sync(name, source, targetdb, synctype) VALUES (‘localhostremoto002’, ‘HERD_LOCALHOST’, ‘remoto002’, ‘swap’);
INSERT INTO bucardo.sync(name, source, targetdb, synctype) VALUES (‘localhostremoto003’, ‘HERD_LOCALHOST’, ‘remoto003’, ‘swap’);
INSERT INTO bucardo.sync(name, source, targetdb, synctype) VALUES (‘remoto001remoto002’, ‘HERD_REMOTO001’, ‘remoto002’, ‘swap’);
INSERT INTO bucardo.sync(name, source, targetdb, synctype) VALUES (‘remoto001remoto003’, ‘HERD_REMOTO001’, ‘remoto003’, ‘swap’);
INSERT INTO bucardo.sync(name, source, targetdb, synctype) VALUES (‘remoto002remoto003’, ‘HERD_REMOTO002’, ‘remoto003’, ‘swap’);
Activamos las sincronizaciones con los siguientes comandos SQL:
UPDATE bucardo.sync SET STATUS=’active’ WHERE name =’localhostremoto001′;
UPDATE bucardo.sync SET STATUS=’active’ WHERE name =’localhostremoto002′;
UPDATE bucardo.sync SET STATUS=’active’ WHERE name =’localhostremoto003′;
UPDATE bucardo.sync SET STATUS=’active’ WHERE name =’remoto001remoto002′;
UPDATE bucardo.sync SET STATUS=’active’ WHERE name =’remoto001remoto003′;
UPDATE bucardo.sync SET STATUS=’active’ WHERE name =’remoto002remoto003′;
.
Activando Bucardo.
Si es por primera vez que se activa Bucardo se necesita crear una carpeta «mkdir /var/run/bucardo/«. Luego se ejecuta el comando «bucardo_ctl -dbuser=’bucardo’ -dbhost=’localhost’ -dbpass=’bucardo’ start –debugfile=1«.

Para verificar que todo se encuentre bien se ejecuta «bucardo_ctl -dbuser=’bucardo’ -dbhost=’localhost’ -dbpass=’bucardo’ status«.
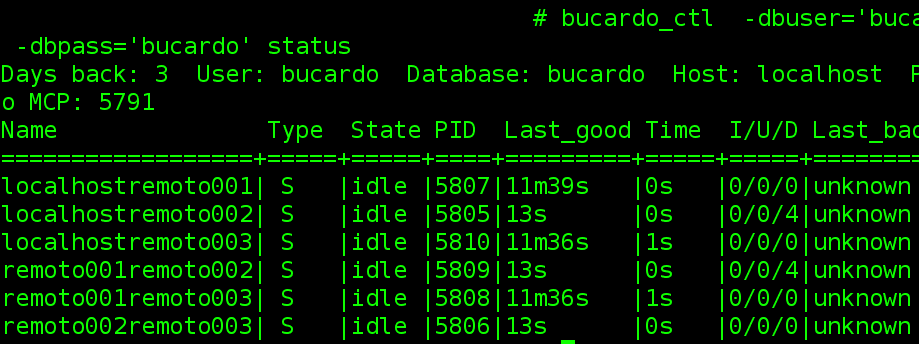
Detengamos por un momento el demonio de bucardo con «bucardo_ctl -dbuser=’bucardo’ -dbhost=’localhost’ -dbpass=’bucardo’ stop” y ejecutemos “bucardo_ctl -dbuser=’bucardo’ -dbhost=’localhost’ -dbpass=’bucardo’ status«, si aparece la linea en rojo que se muestra en la siguiente imagen es que Bucardo no se encuentra en servicio.
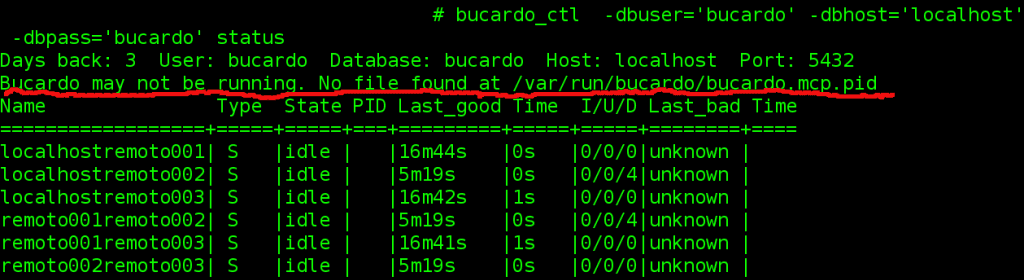
Ahora probemos la sincronización con un nodo «down» o sin PostgreSQL en servicio (en este ejemplo colocaremos en «down» al remoto002).
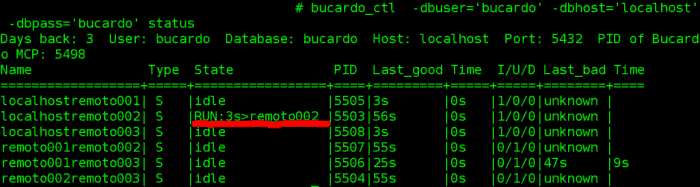
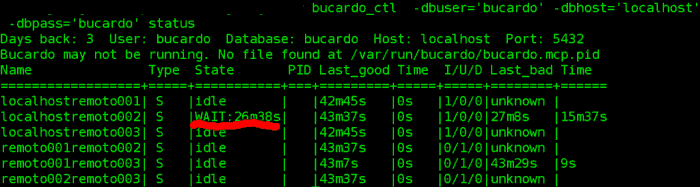
Observemos que las bases de datos no se sincronizan bien (verifiquen en la imagen anterior la linea roja). Este problema se soluciono con check_postgres y un script bash que se realizo para la verificación de los nodos que estaban «up» o «down«.
Primero tenemos que instalar check_postgres. Bajamos check_postgres de la página oficial de Bucardo, se descomprime la carpeta, se logea como root en un termina, entramos en la carpeta que descomprimimos, ejecutamos los siguientes comando en consola «perl Makefile.PL«->»make«-> «make install«. Ya en este punto tenemos instalado check_postgres y para probarlo ejecutamos el siguiente comando
«check_postgres.pl –action=connection –db=repli -u bucardo –dbpass=bucardo –host=localhost«

La comprobación se realizo en la maquina “localhost” con la base de datos “repli”, como resultado se mostro “POSTGRES_CONNECTION OK”.
Ahora vamos a generar un script bash llamado “script_bucardo.sh”:
#!/bin/bash # Script generado por Arturo J. Delgado S. # [email protected] patron="POSTGRES_CONNECTION OK"; for i in `seq 1 3` do host="remoto00$i" VERIFICAR=$(check_postgres.pl --action=connection --db=repli -u bucardo --dbpass=bucardo --host=$host) case $VERIFICAR in *"$patron"*) ACTIVOS[$i]=$i; echo "Host $host encontrado.";; *) INACTIVOS[$i]=$i; echo "Host $host NO encontrado" ;; esac done export PGPASSWORD=1 for i in ${ACTIVOS[*]} do psql -h localhost -U postgres -d bucardo -c "UPDATE bucardo.sync SET STATUS='active' WHERE name like'%00$i%';" done for i in ${INACTIVOS[*]} do psql -h localhost -U postgres -d bucardo -c "UPDATE bucardo.sync SET STATUS='inactive' WHERE name like'%00$i%';" done unset PGPASSWORD bucardo_ctl -dbuser='bucardo' -dbhost='localhost' -dbpass='bucardo' restart --debugfile=1
OJO: Los host de las base de datos deben estar en /etc/hosts o en el DNS de la organización, ya que check_postgres no busca por IP sino por nombre.
Se corre el script con «./script_bucardo.sh» o «bash script_bucardo.sh» y se debería verificar la sincronización de las bases de datos:
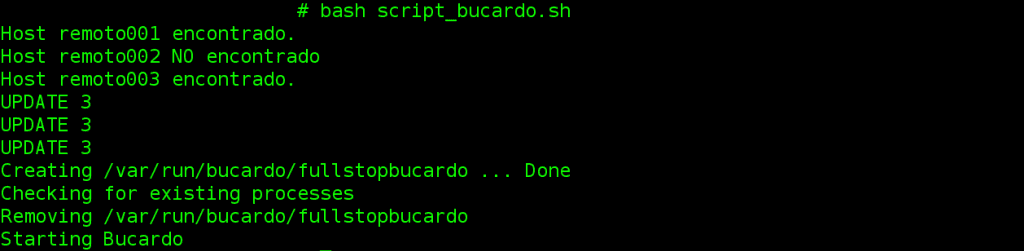

Con la verificación del estatus de Bucardo, comprobamos que, todos las sincronizaciones que contengan nombre “remoto002” están en off y que las demás bases de datos se encuentran sincronizandose y en línea, ya que, tienen sus PID activos y trabajando.
Ahora colocaremos en “up” al host remoto002 y corremos de nuevo el script “script_bucardo.sh”:

Vemos que las bases de datos se sincronizarón exitosamente luego de correr el script, señalando las conexiones que tuvieron problemas y hace cuanto tiempo ocurrió el problema. De igual forma están los PID en todas la sincronizaciones.
Por último se tiene que colocar en el crontab el script para que cada cierto tiempo se realicé la comprobación de las bases de datos. El archivo a modificar es “/etc/crontab” y al final se coloca una línea como en la imagen indica:

.
Arturo J. Delgado S.
Python – wxPython – PostgreSQL
Referencias:
http://www.pcrednet.com/blog/item/7-replicacion-base-de-datos-postgresql-84-con-bucardo
http://www.scribd.com/doc/124248224/Replicacion-PostgreSQL
http://es.wikipedia.org/wiki/PostgreSQL
http://bucardo.org/
http://wiki.postgresql.org/wiki/Replication,_Clustering,_and_Connection_Pooling


Buenas , excelente material , sin embargo acabo de implementar ssl en el servidor y al quitar los privilegios a bucardo para que solo se pueda conectar sslmode=verify-full , no se como configurar la conexion en /usr/local/binbucardo , y como seria la conexion enviando los certificados en la tabla db de bucardo , agradezco si me puede ayudar . Dios le Bendiga.